
The Vision
A job was outsourced to a service provider, and now it is time to reconcile the returned invoice.
The service writer takes an image of their physical invoice, and uploads it to create a digital record. Upon upload, each line item, invoice reference number, important contact information, and service notes are extracted and logged. A warning is also surfaced: "This invoice total is 40% greater than its corresponding service estimate." Instantly, the service writer is able to schedule a follow-up. A week later, the invoice is corrected, uploaded once more, and the total bill comes in at the near-expected estimate total. Not only is money saved here, but the time spent verifying, inputting, and calculating invoice totals is reduced to a few moments of processing and a brief review. In this scenario, admin can use their time to catch errors rather than risk producing them.
The Reality
Today the costly reality is that fleet admin and service writers dedicate many hours to the aforementioned costly process. They input, cross-reference, check, and double-check their work to make sure physical invoices are digitized and properly archived for bookkeeping and audit trails. And although an automated process for this sounds like a dream-come-true, there is a reason we still have experts owning the entire lifecycle of a service invoice: real-world data is messy and unstructured. It's unpredictable. An invoice format that may work for one service provider may miss some crucial details that another needs. These discrepancies require an attention to detail only experienced service writers could reconcile.
Our Approach
Axle is building automation for this workflow with service writers in mind, guided by three core goals: accuracy, transparency, utility. With these in mind, our system is devised into a 3-layer approach, with each layer acting as an agent for each individual goal.
The system functions like a three-tier financial audit team: the first layer reads and structures the invoice, the second traces and validates where each piece of information originated within the document itself, and the third cross-checks the results against broader operational context and historical records. Together, the layers reduce manual reconciliation work while increasing transparency and confidence in the extracted data.
Accuracy Layer: Structured Reasoning via Modern Vision Language Model
This layer is responsible for getting the right answers: the fields and line items a service writer actually cares about.
The focus here is on the core of the invoice, putting a reasoning model into the role of a service writer and setting it on the task of the initial pass. In order to do so accurately, we first needed to understand what a service writer is looking for in an invoice.
What are these writers looking for? Do we know which estimate this invoice ties to? How are different invoice items reconciled differently? What are the common errors in an invoice?
To answer these questions and select the best model, we developed an internal invoice benchmarking system to rank model results on line item and metadata accuracy to select the best model for this task.
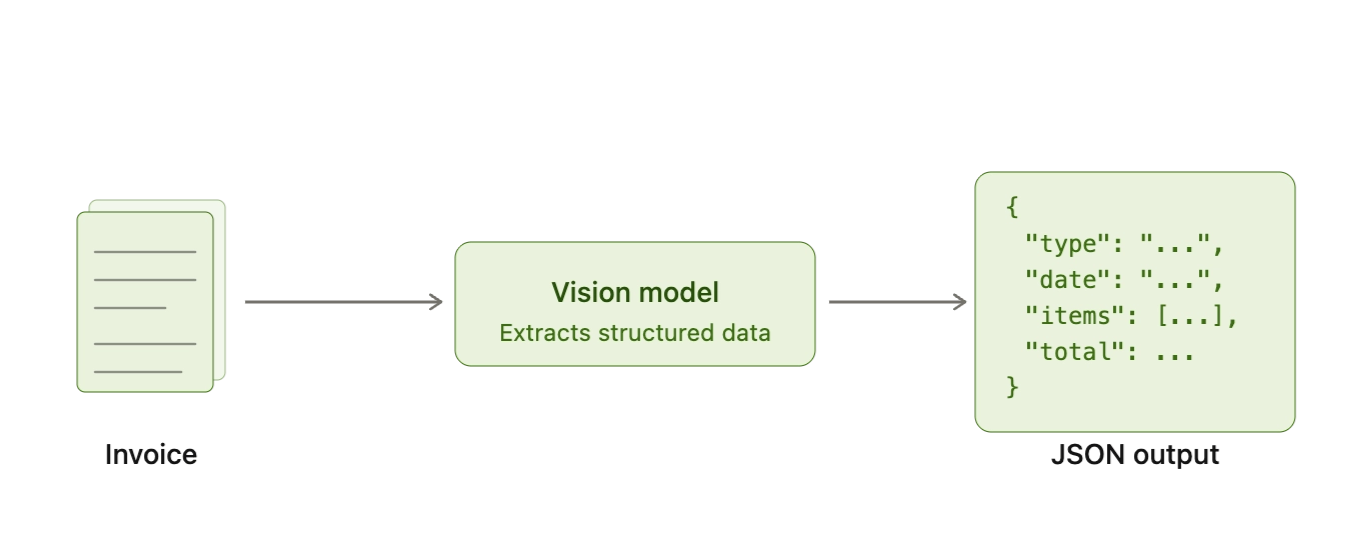
In practice, this layer is an opinionated extraction pass. We prompt the vision reasoning model to return a normalized JSON schema that mirrors how service writers actually review an invoice, with a strict separation between:
- Header + parties: invoice number, dates, vendor, ship-to, bill-to, tax ID
- Financials: subtotal, taxes and fees, discounts, total, payment terms
- Line items: description, quantity, unit price, labor and parts splits, shop supplies, environmental fees
- Service context: unit or VIN, RO and WO references, technician notes, mileage, and any warranty flags
To keep outputs consistent across wildly different invoice templates, we also impose validation rules at generation time, such as required fields, numeric typing, currency formatting, and line-item total checks quantity × unit price ≈ line total. When the model cannot confidently infer a field, it must return null with a short rationale rather than guessing. This creates predictable downstream behavior and makes failures easy to audit.
Finally, we convert the structured result into the objects the rest of our system needs. Line items become deterministic rows that can be matched, de-duplicated, and compared against estimates, historical repairs, and expected pricing bands. In this way, this layer is the first step in transforming an unpredictable invoice into a record that the following layers can validate.
Transparency Layer: Unstructured Data via Primitive OCR Package
This layer is responsible for traceability: providing where and how confidently each extracted value came from on the document.
This is all about helping service writers have the proper information they need to audit our results, increasing workflow reliability and efficiency. To save service writer time by reducing manual input, this layer focuses on audit accessibility, answering the questions:
Where on the invoice did the vision model pull the information? How confident are we in our extractions? How can we make these details accessible to the service writer?
We don't use OCR to decide values, we use it to prove and locate them. To answer these questions, we employ a more primitive second-layer approach to OCR via popular open-source OCR packages. There are many open-source OCR packages, with the most popular being:
- Tesseract: A mature, CPU-first OCR engine (100+ languages) that works best on clean, machine-printed text, but can struggle with complex invoice layouts.
- PaddleOCR: A fast, high-accuracy toolkit that performs well on structured documents like invoices and tables, bridging classic OCR and modern document processing.
- EasyOCR: A lightweight PyTorch-based library with a clean implementation that is easy to integrate across a variety of scripts.
Any of these can produce token boxes + confidences; the specific engine is swappable. These packages are useful to our transparency layer, as their prediction artifacts come with certain metadata that helps us employ a transparency pass on the initial structured data. To put it simply, we are able to extract confidence scores and document locations of items in the invoice. This unstructured data is then able to "handshake" with our structured responses from the first layer, creating a traceable set of extractions complete with confidence scores and document locations, significantly improving the speed at which a service writer can audit results. For each extracted field (e.g., invoice number), we store the OCR token span and bounding boxes that most strongly support it, plus a confidence score. Over time, these artifacts become the backbone for debugging and continuous improvement, because every extraction error can be traced back to a specific region on the invoice and a specific OCR token sequence.
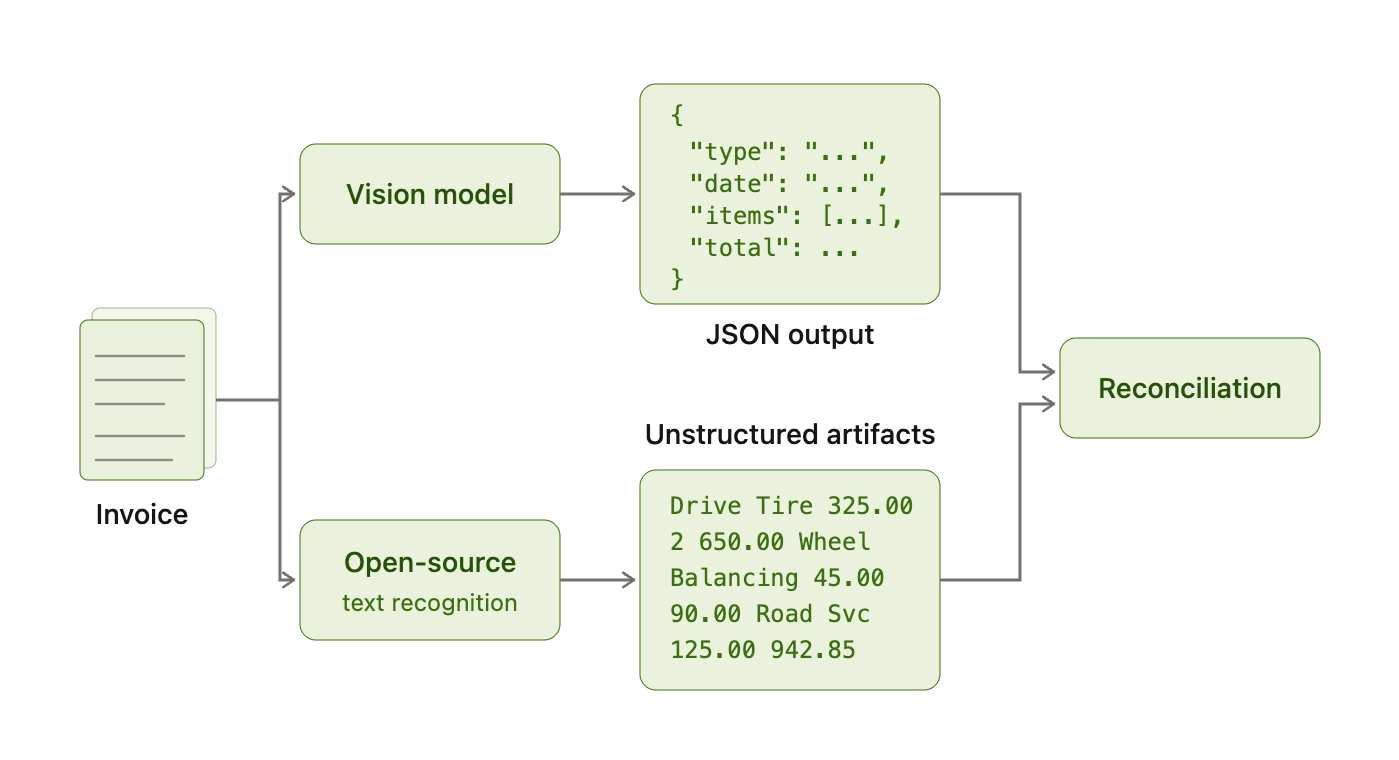
At the reconciliation stage, we do not "vote" between the vision model and OCR or pick a winner. We treat the vision model's extracted fields as truth. This lets us use our OCR package as a find-and-locate tool, pinning each value to a bounding box and a pixel-grounded confidence score. Disagreements between these two modes trigger a fallback to the original result from our accuracy layer (vision model), marked as low confidence and with no associated bounding box. Service writers are then prompted to review such cases and update the values manually as needed.
At Axle we strive to surface only the most accurate confidence scores and document locations. One trick we employ is a price-grounded approach for reconciling invoice line items. Occasionally, an invoice receipt will include unstructured notes with extraneous details about a repair that are not necessary for a service writer's audit. In the same vein, the core work description is almost always presented in line with the price of the labor. By anchoring on line item prices where they are found, we perform a y-banded search across the unstructured extractions to locate the line descriptions found by the vision model. In doing so, we reduce the reconciliation search space by over 90%, increasing match accuracy and audit transparency.

Utility Layer: Building a Context via the Axle Ecosystem
This layer is responsible for "does this make sense?" checks: comparing the invoice to estimates, history, and expectations.
The strength of Axle lies not in the vision models we use to power the text recognition engine, but in Axle's ability to build a context surrounding the invoice. Along with an invoice, there are also oftentimes additional details that require the checks-and-balances that expert service writers always look for. The final layer of our invoice processing pipeline helps to surface as many of these details at one time, looking for answers to the following questions:
How does this invoice total compare to the estimate we received? What was the turnaround time here? Do the invoice line descriptions match what we would expect for this repair? Was this work VMRS coded?
Each of these details need to be answered before an invoice can be marked complete, approved, and paid out. Axle works to surface these details when relevant alongside the invoice when it is processed, reducing the painstaking process of invoice validation into a quick audit process, freeing up the admin to tackle more pressing issues in the shop.
Common examples of these flags include:
- Total exceeds estimate by >X%
- Labor rate outside historical band for this customer/provider
- Duplicate invoice number detected
- Line descriptions don't match expected repair type
In practice, this layer combines deterministic checks, learned expectations, and customer-specific rules to generate actionable flags. That might include matching invoices to the right estimate and RO, detecting outlier labor rates or parts markups, validating taxes and fees against local norms, and highlighting discrepancies between technician notes and billed work. The outcome is a set of actionable cues that mirrors how an experienced service writer already does their job.

Remarks
Accurate invoice extraction is only the starting point. Modern vision reasoning models can reliably turn a photo of an invoice into the structured fields service writers and fleet admins need: header details, totals, and normalized line items. But if the system cannot explain why it produced a value, teams are left doing the same slow work in a different form: re-checking totals, hunting for where a number came from, and rebuilding trust one invoice at a time.
Axle's approach makes the result auditable. We pair the structured, opinionated extraction pass with a transparency layer built on primitive OCR artifacts, using token locations and confidence signals to "handshake" extracted fields back to the exact regions on the document. With that traceability in place, the utility layer can then compare invoices to estimates, repair history, and expected pricing to surface actionable flags. The outcome is an invoice workflow that is not just automated, but reviewable: faster audits, fewer costly mistakes, and clearer confidence in every approval.